自从Ele偶然发现我大深圳图书馆的藏书紧跟时代潮流,以及以前不知道的预借功能和邮寄功能之后,amazon的unlimited就被我毫不留情地打入冷宫,然后几年前办理过的深图借书证开始进入宠妃行列。至此,Ele便过上了在豆瓣mark书,然后跑到深圳图书馆找书的日子。
这里要安利深图的预借和邮寄功能。可以预借的书提交预借申请后,图书馆就会帮你找书,然后投递到指定的地方,接下来只需要带着图书证去取书即可。如果你不想多走几步的话,那么对于那些标明可以邮寄的书籍,仅需6软妹币,快递上门不是梦~~
虽然说在图书馆找书这种事已经基本可以交给图书馆了,但是还是要打开深图的页面搜索一下是否有你想要的图书。对于懒癌晚期患者Ele来说,要在豆瓣深图切来切去也是烦得不要不要的,更何况,有时候你根本在深图上搜不到你要的书籍。
不想做无用功,所以Ele把主意打到了chrome扩展程序<( ̄︶ ̄)>。
啰嗦了那么久,下面进入正题。
简个介
chrome扩展程序是可以修改/加强chrome浏览器功能的程序,使用前端语言,例如HTML、javas和CSS进行编写。
一个安装好了的chrome扩展程序大概是这个样子的:

你可以在chrome网上应用商店上下载安装别人发布的扩展程序。如果找不到满足你想要功能的,也可以自食其力,自己写一个。
下面,我们就来写我们的第一个chrome扩展程序吧。
第一行代码
这里要完成的扩展程序将实现这样一个功能:读取当前页面(以豆瓣读书为例)的书籍名,然后在深图搜索相关信息,并将其展示在弹出页面中。
首先,我们得新建一个目录放置扩展程序相关的文件。这里,我将其命名为searchSZlib。
接下来,需要在这个目录下创建一个名为manifest.json的manifest文件。这是一个json格式的文件,保存了扩展程序的元数据(扩展名、描述、版本号等)。此外,我们还会用它来告诉chrome,这个扩展程序将要做什么、需要什么权限等等。关于这个文件的详细信息,可以参考manifest文件格式文档。
这里,我们的manifest.json长这样:
1 | { |
这里说明一下: * manifest_version,name,version是必填字段,分别表示扩展程序要求的manifest文件格式版本号(整型,对于chrome 18,必须填2),扩展程序的主要标识(最大45个字符,会展示在安装窗口、扩展管理页面和chrome商店上),扩展版本号。 * description:推荐填写字段。扩展的描述信息,必须同时适于展示在浏览器的扩展管理页面和chrome商店上。 * browser_action:可选字段,表示浏览器行为。 - default_icon:可选字段,出现在chrome工具栏上的扩展程序图标。支持旧式语法(即上面代码中的字符串格式)。新式写法如下: 1
2
3
4
5"default_icon": {
"16": "images/icon16.png",
"24": "images/icon24.png",
"32": "images/icon32.png"
}default_popup:可选字段,指定用户点击扩展程序图标的时候弹出的HTML页面。 * permissions:可选字段,声明扩展程序所需权限。权限可以是某个已知字符串(例如“geolocation”),或者匹配要访问的一个/多个主机的模式。这里,由于我们需要访问当前标签页,所以声明了activeTab权限。声明tabs权限,以备可以点击搜索结果时在新的标签中展示页面信息(即调用chrome.tabs API)。另外,因为我们还要访问深图,所以还得把深图的域名加上。 * background:可选字段。当你需要扩展程序常驻后台的时候,就需要声明此字段的内容了。通常,后台页面是不需要什么布局的,因此仅使用JavaScript文件就可以了。如果指定了scripts,那么后台页面将会是一个包含该属性中列出的每一个JavaScript文件的页面。
声明完manifest.json之后,我们就要准备manifest.json中提到的两个资源:icon.png和search.html了。这就完完全全是前端的事了。
我们把图标保存到searchSZlib下,并在同个目录下新建search.html文件。因为我们只需要点击扩展程序,然后展示搜索结果,所以这个HTML文件比较简单:
1 |
|
我们只需要两个div,一个表示搜索状态,另一个展示搜索结果。另外,因为JavaScript写起来太麻烦了(其实是因为Ele是个前端渣(ノへ ̄、)捂脸),所以还得引入jQuery文件。
接下来准备search.js。search.js需要完成的工作是: 1. 搜索图书。查看深图搜书页面,通过开发者工具可以看到请求的URL是"http://www.szlib.org.cn/Search/searchshow.jsp?v_tablearray=bibliosm,serbibm,apabibibm,mmbibm,&v_index=title&v_value=" + encodeURIComponent(书名) + "&sortfield=score&sorttype=desc" 2. 提取搜索结果列表。审查页面,可以看到搜索结果都放在<ul class="booklist"></ul>中。 3. 将搜索结果填充到<div id="searchresult"></div>中。这里要注意的是,结果中的链接都是相对路径,因此我们还需要对结果的链接进行进一步的处理,以便点击的时候可以得到真实的页面。 4. 给链接添加click事件,把页面在新的标签页中展示出来。
search.js的详细代码见search.js
最后,该目录所有文件如下: 1
2
3
4
5
6
7
8$ tree
.
└── searchSZlib
├── icon.png
├── jquery-3.2.1.min.js
├── manifest.json
├── search.html
└── search.js
安装一下
代码写完了,我们来用实践检验下成果吧。
打开chrome浏览器菜单 -> 更多工具 -> 扩展程序 -> 开发者模式 -> 加载已解压的扩展程序...,选择searchSZlib目录,然后就可以看到工具栏上出现扩展程序的图标了。现在点击一下图标试试: 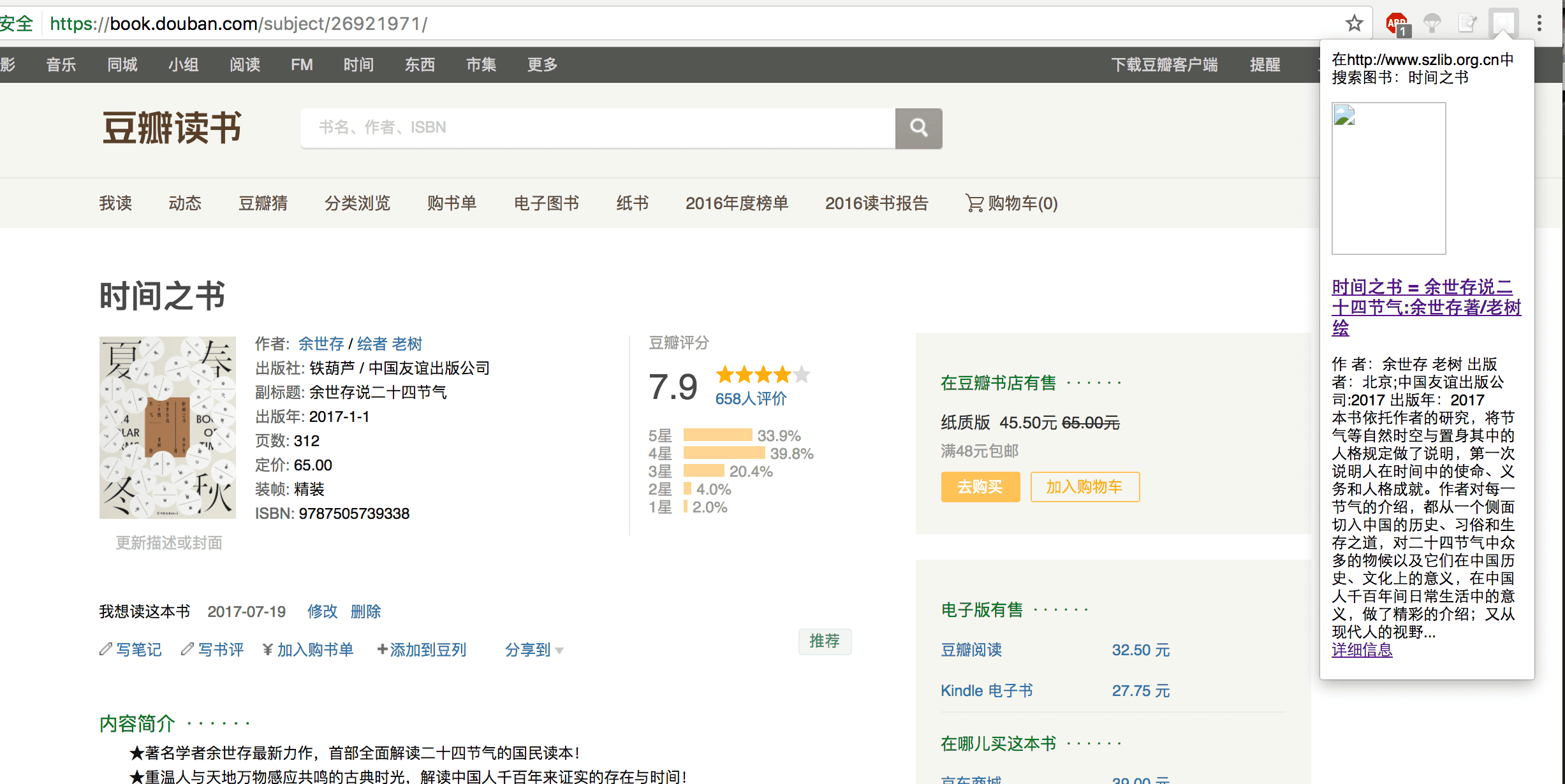
如果代码有变动,只需要点击扩展程序页面中的重新加载即可。
另外,还可以通过右击扩展程序按钮,选择审查弹出内容来进行调试。

